
Redis之Bitmap(位图)
Redis之Bitmap(位图)
Bitmap是一种非常金典的数据结构,在非常多的中间件及高级语言中都有使用及应用,Redis的bitmap实现是采用了字符串对象,其底层是char数组,通过SETBIT、GETBIT、BITCOUNT、BITTOP、BITPOS等命令来操作位。
数据结构
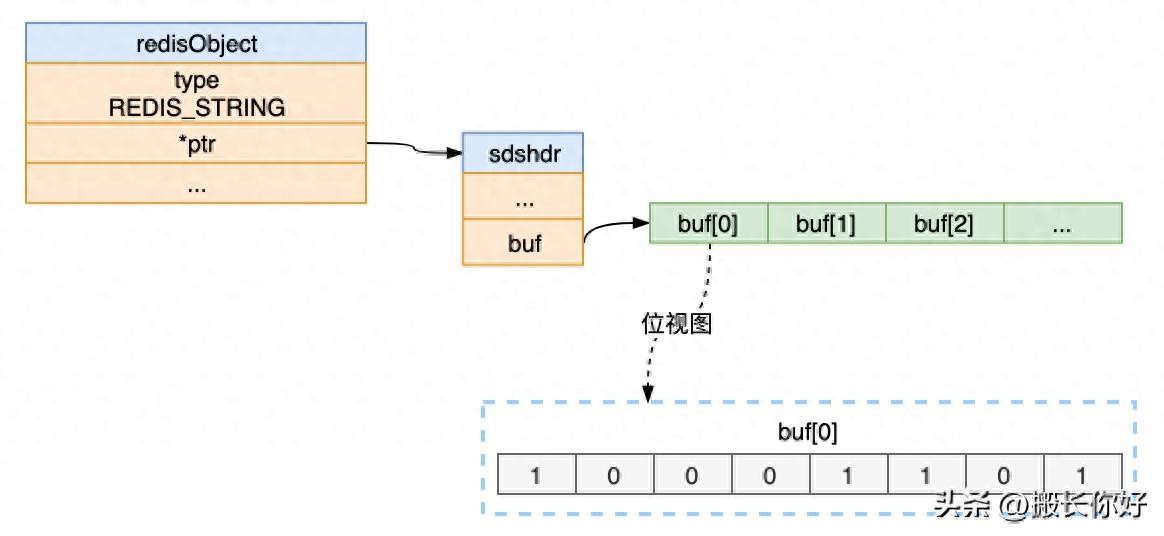
bitmap结构
Bitmap采用字符串对象作为底层存储,字符串对象是一个char[] buf组成,每个char有8个比特位。sds字符串是二进制安全的数据结构,而且可以直接使用sds的操作函数处理位。
实现原理
Bitmap的常用操作命令有SETBIT、GETBIT、BITCOUNT、BITTOP、BITPOS等命令。
为了更加直观地了解其实现原理,将字符串对象视图转化为一个二维位矩阵视图,图如下:
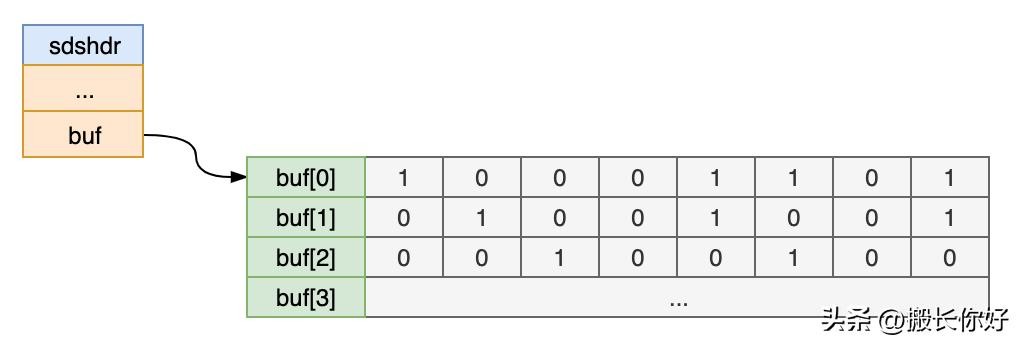
二维位矩阵
二进制位读写顺序
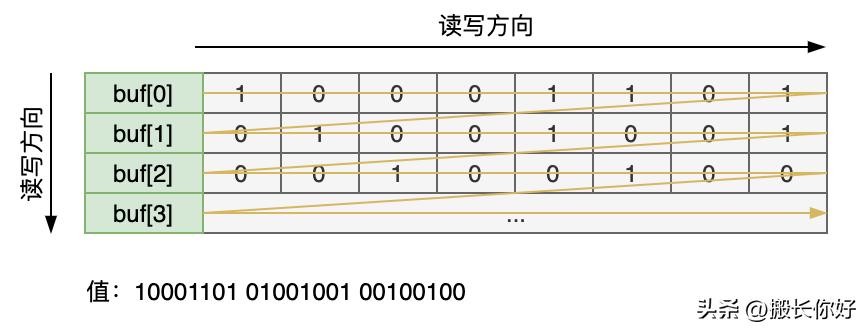
读写顺序
二进制位的读取采用的是逆序保存的(正常二进制位高位在左侧,而该结构左侧是低位),采用逆序存储的好处是,在位扩容是不需要移动原有的位,只需要在数组后追加即可。如果采用正序存储(位低位则需要在数组length-1的位置,与上图所示结构相反),这样就导致每次扩容都需要将原来的二进制位向后移动,大量的位置操作会长时间占用CPU,影响命令的执行效率,从而导致系统的吞吐量急剧降低。
GETBIT 二进制位查询
GETBIT命令是查询指定位的值,GETBIT
通过offset/8可以计算出offset所属字节在buf数组中的位置。通过(offset mod 8)+1可以计算出offset在所在字节的位置(加1是因为从0开始索引的)。通过上面两个步骤就可以找到offset所在位置的二进制位的值。
SETBIT 二进制位设值
SETBIT命令的获取位的位置过程与GETBIT命令实现是基本一致的:
通过offset/8+1可以计算出offset所属字节在buf数组中的位置。通过(offset mod 8)+1可以计算出offset在所在字节的位置。
SETBIT命令还涉及到一个扩容的逻辑存在,比如我们需要设置的位超过了现有容量,那我们必须要做一个扩容。扩容的策略是根据SDS的空间预分配策略,扩容后的控件大小就是:原有大小+SDS预分配大小(不固定)+1字节。
BITCOUNT 统计二进制位为1的位数量
如果在位数量很少的情况下,我们采用逐位遍历还可以接受,时间复杂度为
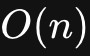
,但如果是一个非常大的Bitmap,有100M时,那么我们逐位查询的次数将达到8亿多次(100*1024*1024*8),这将会严重影响命令的执行效率。因此需要有一些更加高性能的算法来解决这个问题。
查表法:因为我们存储bitmap采用的是char数组的形式存储的,那么我们只需要遍历数组的每一个char(8位),然后去8位映射查表(将00000000-11111111的所有组合包含1的数量存下来,形成一个k-v的映射表),就能快速的得到这个char中位为1的位数量,这样一个100M的Bitmap从8亿多次遍历减少到1亿多次遍历。如果我们将其扩展为32位映射表,那么我们的查询次数将再缩小4倍,变为0.25亿次。
这是一个典型的空间还时间的算法,我们不可能让这个映射表无限变大。而且如果这个映射表很大时CPU缓存行是无法完整放入的(缓存行通常为64字节),这使得大部分查询都不能完全命中CPU的高速缓存,从而做了内存读取,这仍然会影响命令的执行效率。
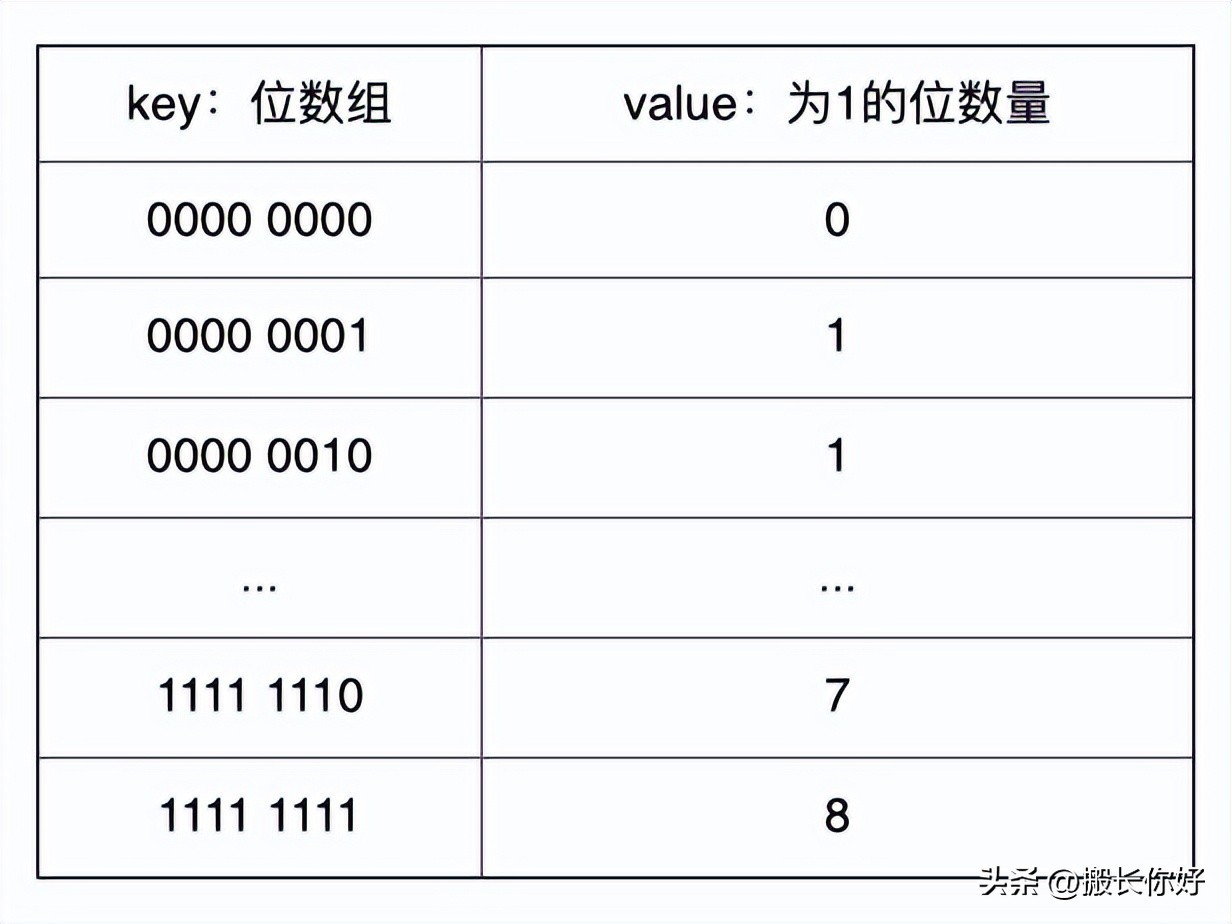
8位的查表法
variable-precision SWAR算法:计算一个数组中非0位的个数,这个问题在数学上被称为“计算汉明重量(Hannming Weight)”,该统计算法被广泛的应用,该算法具体实现可以看下力扣K神的讲解:二进制中1的个数。Redis实现:Redis采用了查表法与SWAR算法组合的方式来实现BITCOUNT命令。具体算法实现如下:/* Count number of bits set in the binary array pointed by 's' and long * 'count' bytes. The implementation of this function is required to * work with an input string length up to 512 MB. */ long long redisPopcount(void *s, long count) { long long bits = 0; unsigned char *p = s; uint32_t *p4; // 映射表 static const unsigned char bitsinbyte[256] = { 0,1,1,2,1,2,2,3,1,2,2,3,2,3,3,4,1,2,2,3,2,3,3, 4,2,3,3,4,3,4,4,5,1,2,2,3,2,3,3,4,2,3,3,4,3,4, 4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,1,2,2,3,2, 3,3,4,2,3,3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5, 4,5,5,6,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4, 5,4,5,5,6,4,5,5,6,5,6,6,7,1,2,2,3,2,3,3,4,2,3, 3,4,3,4,4,5,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,2, 3,3,4,3,4,4,5,3,4,4,5,4,5,5,6,3,4,4,5,4,5,5,6, 4,5,5,6,5,6,6,7,2,3,3,4,3,4,4,5,3,4,4,5,4,5,5, 6,3,4,4,5,4,5,5,6,4,5,5,6,5,6,6,7,3,4,4,5,4,5, 5,6,4,5,5,6,5,6,6,7,4,5,5,6,5,6,6,7,5,6,6,7,6,7,7,8}; // 采用4字节(32位)对齐 /* Count initial bytes not aligned to 32 bit. */ while((unsigned long)p & 3 && count) { bits += bitsinbyte[*p++]; count--; } // 一次处理28字节的数据 /* Count bits 28 bytes at a time */ p4 = (uint32_t*)p; while(count>=28) { uint32_t aux1, aux2, aux3, aux4, aux5, aux6, aux7; aux1 = *p4++; aux2 = *p4++; aux3 = *p4++; aux4 = *p4++; aux5 = *p4++; aux6 = *p4++; aux7 = *p4++; count -= 28; aux1 = aux1 - ((aux1 >> 1) & 0x55555555); aux1 = (aux1 & 0x33333333) + ((aux1 >> 2) & 0x33333333); aux2 = aux2 - ((aux2 >> 1) & 0x55555555); aux2 = (aux2 & 0x33333333) + ((aux2 >> 2) & 0x33333333); aux3 = aux3 - ((aux3 >> 1) & 0x55555555); aux3 = (aux3 & 0x33333333) + ((aux3 >> 2) & 0x33333333); aux4 = aux4 - ((aux4 >> 1) & 0x55555555); aux4 = (aux4 & 0x33333333) + ((aux4 >> 2) & 0x33333333); aux5 = aux5 - ((aux5 >> 1) & 0x55555555); aux5 = (aux5 & 0x33333333) + ((aux5 >> 2) & 0x33333333); aux6 = aux6 - ((aux6 >> 1) & 0x55555555); aux6 = (aux6 & 0x33333333) + ((aux6 >> 2) & 0x33333333); aux7 = aux7 - ((aux7 >> 1) & 0x55555555); aux7 = (aux7 & 0x33333333) + ((aux7 >> 2) & 0x33333333); bits += ((((aux1 + (aux1 >> 4)) & 0x0F0F0F0F) + ((aux2 + (aux2 >> 4)) & 0x0F0F0F0F) + ((aux3 + (aux3 >> 4)) & 0x0F0F0F0F) + ((aux4 + (aux4 >> 4)) & 0x0F0F0F0F) + ((aux5 + (aux5 >> 4)) & 0x0F0F0F0F) + ((aux6 + (aux6 >> 4)) & 0x0F0F0F0F) + ((aux7 + (aux7 >> 4)) & 0x0F0F0F0F))* 0x01010101) >> 24; } // 不足28字节的采用查表法,减少循环次数 /* Count the remaining bytes. */ p = (unsigned char*)p4; while(count--) bits += bitsinbyte[*p++]; return bits; }
应用场景
bitmap的使用非常的广泛,bitmap非常适合二值状态统计类场景(二值状态:也就是集合元素的值只有0和1两种),比如:
通过memberId判断用户登录状态,登录为1,未登录为0。
统计1亿用户的登录情况,使用bitmap最多只需要1亿个bit位约等于12M(1亿/8/1024/1024) ,通过memberId计算出每个会员在bitmap中的offset,offset位的bit值代表一个member的状态,1就是在线,0则为不在线。而如果使用String类型存储的话内存开销达到1GB以上。
拼刀刀某活动统计连续七天签到的用户。
可以每日创建一个bitmap(只保留最近七天的),用于统计当天的用户签到情况,与上一个场景做法一致。若要计算连续七天的登录用户,则只需要将七个bitmap做&操作,统计结果集中位为1的offset,就可以得出连续签到的会员。
资源搜索,资源可以是任意的事物。
例如汽车,我们可以做一个汽车的搜索功能,将市面上所有的汽车做一个特征提取(例如:外观颜色、内饰材质、排量、发动机功率、轮毂大小等等),为每一个具体特征建立一个bitmap结构,然后将所有厂商的车编号(用于确定车型在bitmap的offset),依次录入每辆车的各个特征到对应bitmap中(有此特征则对应offset设置为1)。当我们搜索如:外观红色、排量2.0T、车长4~5m等,首先找到对应特征的bitmap,然后做&操作,结果集中offset为1的车型就是搜索结果。
bitmap的高效存储与计算优势使得其在生产中被广泛的应用,但是其也有一些不足,例如扩容需要大量复制计算及空间分配操作、数据稀疏或者数据的删除出现大量的无效位导致大量空间浪费。
相较于bitmap的这些不足,roaringbitmap则更高效,后续我会介绍到,关注我不迷路。
-

- 2023杨村一中高考成绩捅破了窗户纸,尴尬了谁?家长们应关注两点
-
2026-02-26 07:07:58
-
- 必珍藏!100张全球农场农庄布局图
-
2026-02-26 07:05:44
-

- 【变了个头发,治愈了万千粉丝!】杨紫短发新造型引爆网络新讨论
-
2026-02-25 10:59:20
-

- 中国古镇看嘉兴⑦|新塍:品人间烟火 享古镇至味
-
2026-02-25 10:57:08
-

- 上海海关学院简介,附2023届深造、本科教学、就业质量报告
-
2026-02-25 10:54:52
-

- 澳大利亚4米虎鲨杀人事件
-
2026-02-25 10:52:37
-

- 贺岁大片——《一剑横空》
-
2026-02-25 10:50:23
-

- 闷声干大事,被骂四年后,35岁张碧晨官宣喜讯,终于等到这一天
-
2026-02-25 10:48:09
-

- 携手渤海之滨,共赴山海烂漫,威海移动房交会第十站走进天津
-
2026-02-25 10:45:54
-

- 长达21年的呼叫:每年“愚人节”,中国人提及的“81192”是何意
-
2026-02-25 10:43:40
-

- 伊迪·阿明:7年残杀近30万百姓,对英国女王示爱,索要其内裤
-
2026-02-25 10:41:26
-
- 向安徽人报喜:商合杭铁路开建啦!附最全站点简介
-
2026-02-25 10:39:11
-

- 王者荣耀ADC符文应该如何搭配 通用ADC符文推荐
-
2026-02-11 14:53:26
-

- 泰星Matt取关Aff惹争议,Aff的粉丝却让宋干复婚
-
2026-02-11 14:51:12
-

- 双龙会冷知识“两个成龙”如何做到?香港导演齐发力却败给星爷
-
2026-02-11 14:48:57
-

- 人“五大三粗”,是指哪五大、哪三粗?
-
2026-02-11 14:46:43
-

- 全国315曝光名单公布:守护消费者权益,刻不容缓
-
2026-02-11 14:44:29
-

- 辽M货车将女子撞伤后逃离现场,交警苦口婆心成功劝司机投案
-
2026-02-11 14:42:14
-

- 红色政权的存在
-
2026-02-11 14:40:00
-

- 滇西抗战主战场腾冲.
-
2026-02-11 14:37:46
 一条烟不开封可以放多久?
一条烟不开封可以放多久? 杨幂“等一下,我老公呢”23年了到底什么人还在玩梗认为是她?
杨幂“等一下,我老公呢”23年了到底什么人还在玩梗认为是她? 中国著名相声演员姜昆简历
中国著名相声演员姜昆简历 彭冠英张含韵被曝结婚:低调的幸福爱情婚姻,或许与她的经历有关
彭冠英张含韵被曝结婚:低调的幸福爱情婚姻,或许与她的经历有关 天津女厕所蹲便器被人放置摄像头,偷拍行业背后的肮脏出乎想象
天津女厕所蹲便器被人放置摄像头,偷拍行业背后的肮脏出乎想象 王治郅的妻子周蕾,身材高挑 才貌双全 照片欣赏
王治郅的妻子周蕾,身材高挑 才貌双全 照片欣赏 范冰冰不雅图片 范爷大尺度裸身戏遭曝光
范冰冰不雅图片 范爷大尺度裸身戏遭曝光 扎西顿珠视为信仰的宗庸卓玛与平凡丈夫的爱情,七年卧床不离不弃
扎西顿珠视为信仰的宗庸卓玛与平凡丈夫的爱情,七年卧床不离不弃